0:导引
K-近邻算法(KNN)### 如何进行电影分类众所周知,电影可以按照题材分类,然而题材本身是如何定义的?由谁来判定某部电影属于哪 个题材?也就是说同一题材的电影具有哪些公共特征?这些都是在进行电影分类时必须要考虑的问 题。没有哪个电影人会说自己制作的电影和以前的某部电影类似,但我们确实知道每部电影在风格 上的确有可能会和同题材的电影相近。那么动作片具有哪些共有特征,使得动作片之间非常类似, 而与爱情片存在着明显的差别呢?动作片中也会存在接吻镜头,爱情片中也会存在打斗场景,我们 不能单纯依靠是否存在打斗或者亲吻来判断影片的类型。但是爱情片中的亲吻镜头更多,动作片中 的打斗场景也更频繁,基于此类场景在某部电影中出现的次数可以用来进行电影分类。本章介绍第一个机器学习算法:K-近邻算法,它非常有效而且易于掌握
1:k-近邻算法原理
简单地说,K-近邻算法采用测量不同特征值之间的距离方法进行分类。- 优点:精度高(计算距离)、对异常值不敏感(单纯根据距离进行分类,会忽略特殊情况)、无数据输入假定(不会对数据预先进行判定)。- 缺点:时间复杂度高、空间复杂度高。- 适用数据范围:数值型和标称型。
工作原理
存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输人没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前K个最相似的数据,这就是K-近邻算法中K的出处,通常*K是不大于20的整数。最后 ,选择K个最相似数据中出现次数最多的分类,作为新数据的分类回到前面电影分类的例子,使用K-近邻算法分类爱情片和动作片。有人曾经统计过很多电影的打斗镜头和接吻镜头,下图显示了6部电影的打斗和接吻次数。假如有一部未看过的电影,如何确定它是爱情片还是动作片呢?我们可以使用K-近邻算法来解决这个问题。

即使不知道未知电影属于哪种类型,我们也可以通过某种方法计算出来。首先计算未知电影与样本集中其他电影的距离,如图所示。
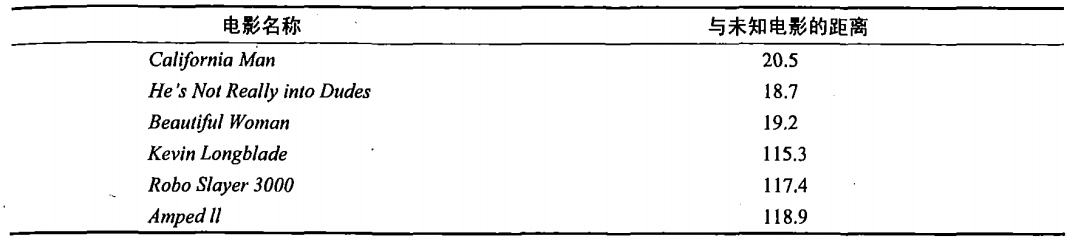
现在我们得到了样本集中所有电影与未知电影的距离,按照距离递增排序,可以找到K个距 离最近的电影。假定k=3,则三个最靠近的电影依次是California Man、He's Not Really into Dudes、Beautiful Woman。K-近邻算法按照距离最近的三部电影的类型,决定未知电影的类型,而这三部电影全是爱情片,因此我们判定未知电影是爱情片。
欧几里得距离(Euclidean Distance)
欧氏距离是最常见的距离度量,衡量的是多维空间中各个点之间的绝对距离。公式如下:

2:在scikit-learn库中使用k-近邻算法
分类问题:from sklearn.neighbors import KNeighborsClassifier 0)一个最简单的例子 对电影进行分类 import pandas as pdimport numpy as np# 导入数据data = pd.read_excel('../../my_films.xlsx')# 样本数据的提取feature = data[['Action lens','Love lens']]target = data['target']# 训练模型from sklearn.neighbors import KNeighborsClassifierknn = KNeighborsClassifier(n_neighbors=3) # n_neighbors 就是k ,n_neighbors=3是找到附近的3个邻居knn.fit(feature,target) # 传入数据 模型训练完成# 进行预测knn.predict([[19,19]]) # array(['Love'], dtype=object)# 一种简单的方法确定k的值 # scoreknn.score(feature,target) 3:预测年收入是否大于50K美元
# 读取adult.txt文件,最后一列是年收入,并使用KNN算法训练模型,然后使用模型预测一个人的年收入是否大于50df = pd.read_csv(r'C:\Users\lucky\Desktop\爬虫+数据\oldBoy数据授课\1.KNN\1-KNN\data\adults.txt')# 查看数据df.head(2)# 获取年龄、教育程度、职位、每周工作时间作为机器学习数据# 获取薪水作为对应结果#样本数据的提取feature = df[['age','education_num','occupation','hours_per_week']]target = df['salary']# 查看数据feature.head(3) age education_num occupation hours_per_week0 39 13 Adm-clerical 401 50 13 Exec-managerial 132 38 9 Handlers-cleaners 40
# 数据转换,将String类型数据转换为int 因为字符串没办法做运算# 【知识点】map方法,进行数据转换s = feature['occupation'].unique()dic = {}j = 0for i in s: dic[i] = j j += 1feature['occupation'] = feature['occupation'].map(dic)# 查看数据feature.head() age education_num occupation hours_per_week0 39 13 0 401 50 13 1 132 38 9 2 403 53 7 2 404 28 13 3 40 #样本数据的拆分 32560x_train = feature[:32500]y_train = target[:32500]x_test = feature[32500:]y_test = target[32500:]knn = KNeighborsClassifier(n_neighbors=50)knn.fit(x_train,y_train)knn.score(x_test,y_test)# 0.7868852459016393#使用测试数据进行测试print('真实的分类结果:',np.array(y_test))print('模型的分类结果:',np.array(knn.predict(x_test)))真实的分类结果: ['<=50K' '<=50K' '<=50K' '<=50K' '>50K' '<=50K' '>50K' '<=50K' '<=50K' '<=50K' '>50K' '<=50K' '<=50K' '>50K' '<=50K' '<=50K' '<=50K' '<=50K' '>50K' '>50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '>50K' '<=50K' '>50K' '>50K' '<=50K' '<=50K' '>50K' '<=50K' '>50K' '>50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '>50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '>50K' '<=50K' '<=50K' '>50K' '<=50K' '<=50K' '>50K']模型的分类结果: ['<=50K' '<=50K' '>50K' '<=50K' '>50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '>50K' '>50K' '<=50K' '<=50K' '>50K' '<=50K' '>50K' '<=50K' '<=50K' '<=50K' '<=50K' '>50K' '<=50K' '<=50K' '<=50K' '<=50K' '>50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '>50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K']knn.predict([[50,12,4,50]])# array(['>50K'], dtype=object)